使用Spring AI 和 LLM 实现数据库查询 AIDocumentLibraryChat 项目已扩展为支持提问来搜索关系数据库 。用户可以输入一个问题,然后嵌入搜索相关的数据库表和列来回答问题。然后,LLM 获取相关表的数据库架构,并根据找到的表和列生成一个 SQL 查询,来展示结果回答问题。
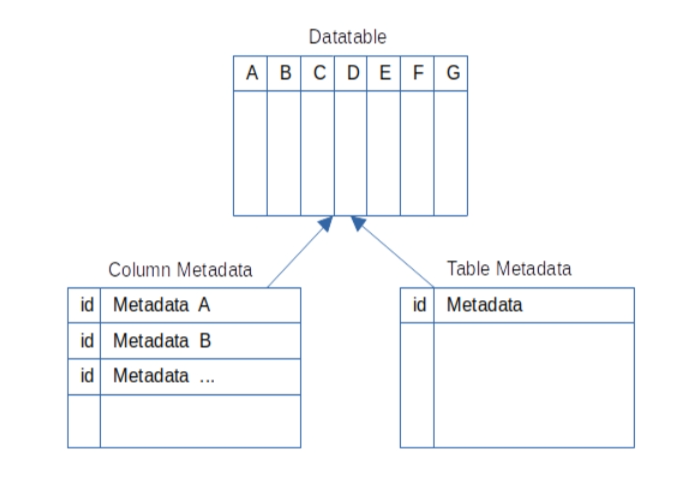
数据集和元数据 使用的开源数据集有 6 个表,彼此之间有关系。它包含有关博物馆和艺术品的数据。为了获得有用的问题查询,必须为数据集提供元数据,并且必须在嵌入中转换元数据。
为了使 LLM 能够找到所需的表和列,它需要知道它们的名称和描述。对于像 museum 表这样的所有数据表,元数据都存储在 column_metadata 和 table_metadata 表中。它们的数据可以在以下文件中找到: column_metadata.csv 和 table_metadata.csv 。它们包含表或列的唯一 ID、名称、描述等。该描述用于创建与问题嵌入进行比较的嵌入。描述的质量对结果有很大的影响,因为更好的描述会使嵌入更精确。提供同义词是提高质量的一种选择。表元数据包含表的模式,以便仅向 LLM 提示符添加相关的表模式。
嵌入 为了在 Postgresql 中存储嵌入,使用了向量扩展。可以使用 OpenAI 端点或 Spring AI 提供的 ONNX 库创建嵌入。创建了三种类型的嵌入:
Tabledescription嵌入Columndescription嵌入Rowcolumn嵌入
Tabledescription 嵌入有一个基于表描述的向量,嵌入有 tablename、datatype = table 和元数据中的元数据 id。Columndescription 嵌入有一个基于列描述的向量,嵌入有表名、带列名的数据名、datatype = column 和元数据中的元数据 id。
Rowcolumn 嵌入有一个基于内容行列值的向量。用于美术作品的样式或主题,以便能够使用问题中的值。元数据具有datatype = row、作为 dataname 的列名、表名和元数据 id。
实现搜索 搜索有 3 个步骤:
检索嵌入
创建提示
执行查询并返回结果
检索嵌入 为了从具有向量扩展的 Postgresql 数据库中读取嵌入,Spring AI 使用 DocumentVSRepositoryBean 中的 VectorStore 类:
1 2 3 4 5 6 7 @Override public List<Document> retrieve (String query, DataType dataType) { return this .vectorStore.similaritySearch( SearchRequest.query(query).withFilterExpression( new Filter .Expression(ExpressionType.EQ, new Key (MetaData.DATATYPE), new Value (dataType.toString())))); }
VectorStore 为用户的查询 提供相似性搜索。查询在嵌入中转换,并在头值中使用用于数据类型的FilterExpression 返回结果。
TableService 类在 retrieveEmbeddings 方法中使用存储库:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 private EmbeddingContainer retrieveEmbeddings (SearchDto searchDto) { var tableDocuments = this .documentVsRepository.retrieve( searchDto.getSearchString(), MetaData.DataType.TABLE, searchDto.getResultAmount()); var columnDocuments = this .documentVsRepository.retrieve( searchDto.getSearchString(), MetaData.DataType.COLUMN, searchDto.getResultAmount()); List<String> rowSearchStrs = new ArrayList <>(); if (searchDto.getSearchString().split("[ -.;,]" ).length > 5 ) { var tokens = List.of(searchDto.getSearchString() .split("[ -.;,]" )); for (int i = 0 ;i<tokens.size();i = i+3 ) { rowSearchStrs.add(tokens.size() <= i + 3 ? "" : tokens.subList(i, tokens.size() >= i +6 ? i+6 : tokens.size()).stream().collect(Collectors.joining(" " ))); } } var rowDocuments = rowSearchStrs.stream().filter(myStr -> !myStr.isBlank()) .flatMap(myStr -> this .documentVsRepository.retrieve(myStr, MetaData.DataType.ROW, searchDto.getResultAmount()).stream()) .toList(); return new EmbeddingContainer (tableDocuments, columnDocuments, rowDocuments); }
首先,documentVsRepository 用于根据用户的搜索字符串检索带有表/列嵌入的文档。然后,将搜索字符串分成6个单词的块,以搜索具有行嵌入的文档。行嵌入只是一个单词,为了获得低距离,查询字符串必须很短;否则,由于查询中的所有其他单词,距离会增加。然后使用块来检索带有嵌入的行文档。
创建提示词 提示词是通过 createPrompt 方法在 TablesService 类中创建的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 private Prompt createPrompt (SearchDto searchDto, EmbeddingContainer documentContainer) { final Float minRowDistance = documentContainer.rowDocuments().stream() .map(myDoc -> (Float) myDoc.getMetadata().getOrDefault(MetaData.DISTANCE, 1.0f )).sorted().findFirst().orElse(1.0f ); LOGGER.info("MinRowDistance: {}" , minRowDistance); var sortedRowDocs = documentContainer.rowDocuments().stream() .sorted(this .compareDistance()).toList(); var tableColumnNames = this .createTableColumnNames(documentContainer); List<TableNameSchema> tableRecords = this .tableMetadataRepository .findByTableNameIn(tableColumnNames.tableNames()).stream() .map(tableMetaData -> new TableNameSchema (tableMetaData.getTableName(), tableMetaData.getTableDdl())).collect(Collectors.toList()); final AtomicReference<String> joinColumn = new AtomicReference <String>("" ); final AtomicReference<String> joinTable = new AtomicReference <String>("" ); final AtomicReference<String> columnValue = new AtomicReference <String>("" ); sortedRowDocs.stream().filter(myDoc -> minRowDistance <= MAX_ROW_DISTANCE) .filter(myRowDoc -> tableRecords.stream().filter(myRecord -> myRecord.name().equals(myRowDoc.getMetadata() .get(MetaData.TABLE_NAME))).findFirst().isEmpty()) .findFirst().ifPresent(myRowDoc -> { joinTable.set(((String) myRowDoc.getMetadata() .get(MetaData.TABLE_NAME))); joinColumn.set(((String) myRowDoc.getMetadata() .get(MetaData.DATANAME))); tableColumnNames.columnNames().add(((String) myRowDoc.getMetadata() .get(MetaData.DATANAME))); columnValue.set(myRowDoc.getContent()); this .tableMetadataRepository.findByTableNameIn( List.of(((String) myRowDoc.getMetadata().get(MetaData.TABLE_NAME)))) .stream().map(myTableMetadata -> new TableNameSchema ( myTableMetadata.getTableName(), myTableMetadata.getTableDdl())).findFirst() .ifPresent(myRecord -> tableRecords.add(myRecord)); }); var messages = createMessages(searchDto, minRowDistance, tableColumnNames, tableRecords, joinColumn, joinTable, columnValue); Prompt prompt = new Prompt (messages); return prompt; }
首先,过滤掉 rowDocuments 的最小距离。然后创建一个按距离排序的文档列表行。
然后通过使用 TableMetadataRepository 将表名映射到模式 DDL 字符串来创建表记录。
然后对已排序的行文档进行 MAX_ROW_DISTANCE 过滤,并设置 joinColumn、joinTable 和columnValue 值。然后使用 TableMetadataRepository 创建 TableNameSchema 并将其添加到tableRecords 中。
现在可以设置 systemPrompt 中的占位符和可选的 columnMatch:
1 2 3 4 5 6 7 8 9 private final String systemPrompt = """ ... Include these columns in the query: {columns} \n Only use the following tables: {schemas};\n %s \n """ ;private final String columnMatch = """ Join this column: {joinColumn} of this table: {joinTable} where the column has this value: {columnValue}\n """ ;
方法 createMessages(…) 获取用来替换 {columns} 占位符的列集。它获取 tableRecords,用表的 ddl 替换 {schemas} 占位符。如果行距离低于阈值,则在字符串占位符%s处添加属性columnMatch。然后替换占位符 {joinColumn}、{joinTable} 和 {columnValue}。
有了关于所需列的信息、包含这些列的表的模式和行匹配的可选连接的信息,LLM 就能够创建一个合理的 SQL 查询。
执行查询并返回结果 查询在以下方法 createQuery(...) 中执行:
1 2 3 4 5 6 7 8 public SqlRowSet searchTables (SearchDto searchDto) { EmbeddingContainer documentContainer = this .retrieveEmbeddings(searchDto); Prompt prompt = createPrompt(searchDto, documentContainer); String sqlQuery = createQuery(prompt); LOGGER.info("Sql query: {}" , sqlQuery); SqlRowSet rowSet = this .jdbcTemplate.queryForRowSet(sqlQuery); return rowSet; }
首先,调用准备数据和创建 SQL 查询的方法,然后使用 queryForRowSet(…) 在数据库上执行查询。返回 SqlRowSet。TableMapper 类使用 map(…) 方法将结果转换为 TableSearchDto 类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public TableSearchDto map (SqlRowSet rowSet, String question) { List<Map<String, String>> result = new ArrayList <>(); while (rowSet.next()) { final AtomicInteger atomicIndex = new AtomicInteger (1 ); Map<String, String> myRow = List.of(rowSet .getMetaData().getColumnNames()).stream() .map(myCol -> Map.entry( this .createPropertyName(myCol, rowSet, atomicIndex), Optional.ofNullable(rowSet.getObject( atomicIndex.get())) .map(myOb -> myOb.toString()).orElse("" ))) .peek(x -> atomicIndex.set(atomicIndex.get() + 1 )) .collect(Collectors.toMap(myEntry -> myEntry.getKey(), myEntry -> myEntry.getValue())); result.add(myRow); } return new TableSearchDto (question, result, 100 ); }
首先,创建结果映射的结果列表。然后,对每行迭代 rowSet,以创建列名作为键、列值作为值的映射。这样可以灵活地返回列的数量及其结果。createPropertyName(…) 将索引整数添加到映射键中,以支持重复的键名。
展示 后端 Spring AI 非常支持创建具有灵活占位符数量的提示。创建嵌入和查询向量表也得到了很好的支持。
获取合理的查询结果需要必须为列和表提供的元数据。创建良好的元数据是一项随列和表的数量线性扩展的工作。为需要它们的列实现嵌入是一项额外的工作。
结果是,像 OpenAI 或 Ollama 这样具有“sqlcoder:70b-alpha-q6_K ”模型的 LLM 可以回答以下问题:“显示艺术品名称和具有现实主义风格和肖像主题的博物馆名称。
LLM 可以在边界内回答与元数据有一定契合度的自然语言问题。对于一个免费的 OpenAI 帐户来说,所需的嵌入量太大了,而“sqlcoder:70b-alpha-q6_K”是最小的模型,结果合理。
LLM 提供了一种与关系数据库交互的新方法。在开始为数据库提供自然语言接口的项目之前,必须考虑工作量和预期结果。
LLM 可以帮助解决中小型复杂度的问题,用户应该对数据库有一定的了解。
前端 后端返回的结果是以键为列名和值为列值的映射列表。返回的映射条目的数量是未知的,因此显示结果的表必须支持灵活数量的列。示例 JSON 结果如下所示:
1 { "question" : "..." , "resultList" : [ { "1_name" : "Portrait of Margaret in Skating Costume" , "2_name" : "Philadelphia Museum of Art" } , { "1_name" : "Portrait of Mary Adeline Williams" , "2_name" : "Philadelphia Museum of Art" } , { "1_name" : "Portrait of a Little Girl" , "2_name" : "Philadelphia Museum of Art" } ] , "resultAmount" : 100 }
resultList 属性包含一个带有属性键和值的 JavaScript 对象数组。为了能够在 Angular Material Table 组件中显示列名和值,使用了这些属性:
1 2 protected columnData: Map<string, string>[] = [];protected columnNames = new Set <string>();
table-search.component.ts 的 getColumnNames(…) 方法用于在属性中转换JSON结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 private getColumnNames (tableSearch: TableSearch) : Set<string> { const result = new Set <string>(); this .columnData = []; const myList = !tableSearch?.resultList ? [] : tableSearch.resultList; myList.forEach((value) => { const myMap = new Map <string, string>(); Object.entries(value).forEach((entry) => { result.add(entry[0 ]); myMap.set(entry[0 ], entry[1 ]); }); this .columnData.push(myMap); }); return result; }
首先,创建结果集,并将 columnData 属性设置为空数组。然后,创建 myList 并使用 forEach(…)迭代。对于 resultList 中的每个对象,将创建一个新的 Map。对于对象的每个属性,将创建一个新条目,以属性名作为键,以属性值作为值。在columnData 映射上设置条目,并将属性名称添加到结果集中。将完成的映射推入 columnData 数组,返回结果并设置为 columnNames 属性。
然后在 columnNames 集中可以得到一组列名,在 columnData 中可以得到一个从列名到列值的映射。
模板 table-search.component.html 包含 material 表:
1 2 3 4 5 6 7 8 9 10 11 12 @if(searchResult && searchResult.resultList?.length) { <table mat-table [dataSource ]="columnData" > <ng-container *ngFor ="let disCol of columnNames" matColumnDef ="{{ disCol }}" > <th mat-header-cell *matHeaderCellDef > {{ disCol }}</th > <td mat-cell *matCellDef ="let element" > {{ element.get(disCol) }}</td > </ng-container > <tr mat-header-row *matHeaderRowDef ="columnNames" > </tr > <tr mat-row *matRowDef ="let row; columns: columnNames" > </tr > </table > }
首先,在 resultList中 检查 searchResult 是否存在和对象。然后,使用 columnData 映射的数据源创建表。表头行设置为 <tr mat-header-row *matHeaderRowDef=”columnNames”> 以包含columnNames。表的行和列是用 <tr mat-row *matRowDef=”let row;列:columnNames “ > < / tr >。
单元格是通过迭代 columnname 来创建的: <ng-container *ngFor=”let disCol of columnNames” matColumnDef=”“>。
标题单元格创建: <th mat-header-cell *matHeaderCellDef>。
总结 在 LLM 的帮助下质疑数据库需要对元数据进行一些努力,并且对数据库包含的内容有一个粗略的了解。AI/LLM 不适合创建查询,因为 SQL 查询需要正确性。需要一个相当大的模型来获得所需的查询正确性,并且需要 GPU 加速才能进行生产性使用。
设计良好的 UI,用户可以在其中拖放结果表中的表列,这可能是满足要求的不错选择。Angular Material Components 很好地支持拖放。

 微信
微信 支付宝
支付宝


